AstroSat SSM Data Platform: A Scientific Data Pipeline for ISRO
1. High-Level Summary
Co-developed a terabyte-scale, data platform to democratize access to astrophysical data from the Indian Space Research Organisation’s (ISRO) AstroSat satellite. The system provides a robust backend pipeline and an intuitive web interface for scientists, PhDs, and researchers worldwide to retrieve, process, and analyze data from the Scanning Sky Monitor (SSM). This project was lauded as “outstanding” by the mission’s lead scientists for its profound impact on research efficiency and data accessibility.
2. The Challenge: Unlocking 14 Terabytes of Complex Scientific Data
The AstroSat SSM instrument continuously generates invaluable time-series data, crucial for studying phenomena like X-ray bursts. However, this data, amounting to 14 TB and growing, was locked in a complex ecosystem that presented significant barriers to research:
- Massive Data Aggregation: A single query could result in an aggregated dataset of up to 100 GB, making it unmanageable to download and analyze without specialized processing.
- Time-Consuming Manual Labor: The existing workflow was a disjointed, script-based process. A typical analysis—finding data for a specific source over a date range, processing it, and generating plots—took hours of manual work.
- High Barrier to Entry: The data was stored in a specialized FITS format across a complex directory structure, requiring deep institutional knowledge to navigate and utilize effectively.
Our objective was to create a centralized, performant, and user-friendly platform that could handle this scale and complexity, making the data accessible to the global scientific community.
3. The Solution: An End-to-End Data Pipeline & Analysis Platform
We engineered a comprehensive solution featuring a powerful backend and an intuitive web frontend. I took a leading role in architecting the core data extraction logic and solely developed the platform’s content management system.
a) Core Data Extraction Engine: The heart of the platform is an automated backend pipeline I primarily designed. It transforms the raw, complex archive into analysis-ready packages.
- Terabyte-Scale Processing: Scans the 14 TB data archive, parsing complex FITS files and filtering observations by source, date, and data level.
- Intelligent File Splitting: To manage the massive outputs, the engine automatically splits aggregated FITS files into user-defined, manageable chunks (e.g., 10MB), preventing data overload.
- Automated Data Packaging: For every request, the system generates a complete package including the split FITS files, XML metadata, CSV reports, and source activity plots, which are then compressed into a single ZIP archive for download.
b) High-Performance Caching Layer: To ensure a responsive user experience, especially for common queries, we implemented a robust caching mechanism.
- Drastic Performance Gains: The system uses MD5 hashing to cache the results of completed queries. This reduced the processing time for repeated requests by over 99%, from 15+ minutes for an initial run to ~3 seconds for a cached result.
c) Dynamic Content Management System (CMS): I solely developed a lightweight, Markdown-based CMS to keep the platform’s documentation and guides current.
- Empowering Domain Experts: This system allows ISRO’s scientists—the people with the knowledge—to directly edit and add informational pages using simple Markdown syntax.
- Separation of Concerns: It completely decouples content from code, enabling seamless updates without requiring developer intervention or risking the application’s stability. This ensures the platform’s documentation remains accurate and relevant.
d) Web-Based User Interface & Analysis Tools: The Flask-based web application provides the face of the platform, offering several key workflows:
- Data Extractor: A simple form to query the 14 TB archive and receive a complete, processed data package.
- FITS Inspector: A “quick-look” utility to rapidly generate diagnostic plots (light curves, hardness ratios) for any FITS file.
- Transient Detector: A statistical analysis tool that uses rolling z-score calculations to automatically detect potential X-ray bursts and other transient events.
4. Key Outcomes & Impact
- Democratized Data Access: Transformed a complex internal archive into a resource, enabling students, PhDs, and international researchers to conduct novel studies.
- Accelerated Scientific Research: Reduced the time for data retrieval and basic processing from hours to minutes, a time-saving of over 95%, allowing scientists to focus on analysis rather than data wrangling.
- Acclaimed by ISRO: The project was formally recognized as “outstanding” by Dr. Ramadevi M.C. and the entire AstroSat SSM payload team for its performance, usability, and strategic importance.
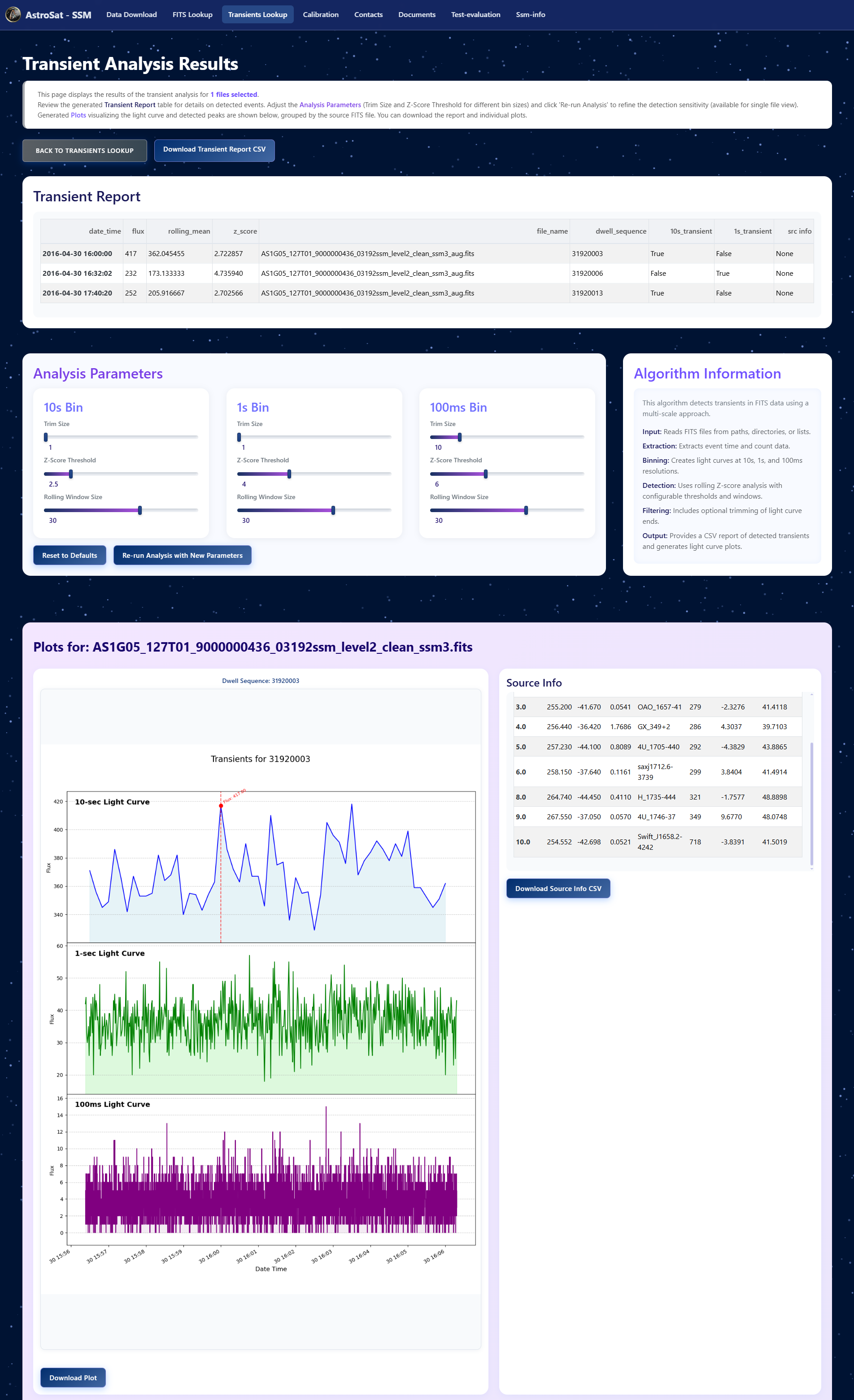
FITS Transient Analyzer

Home Page
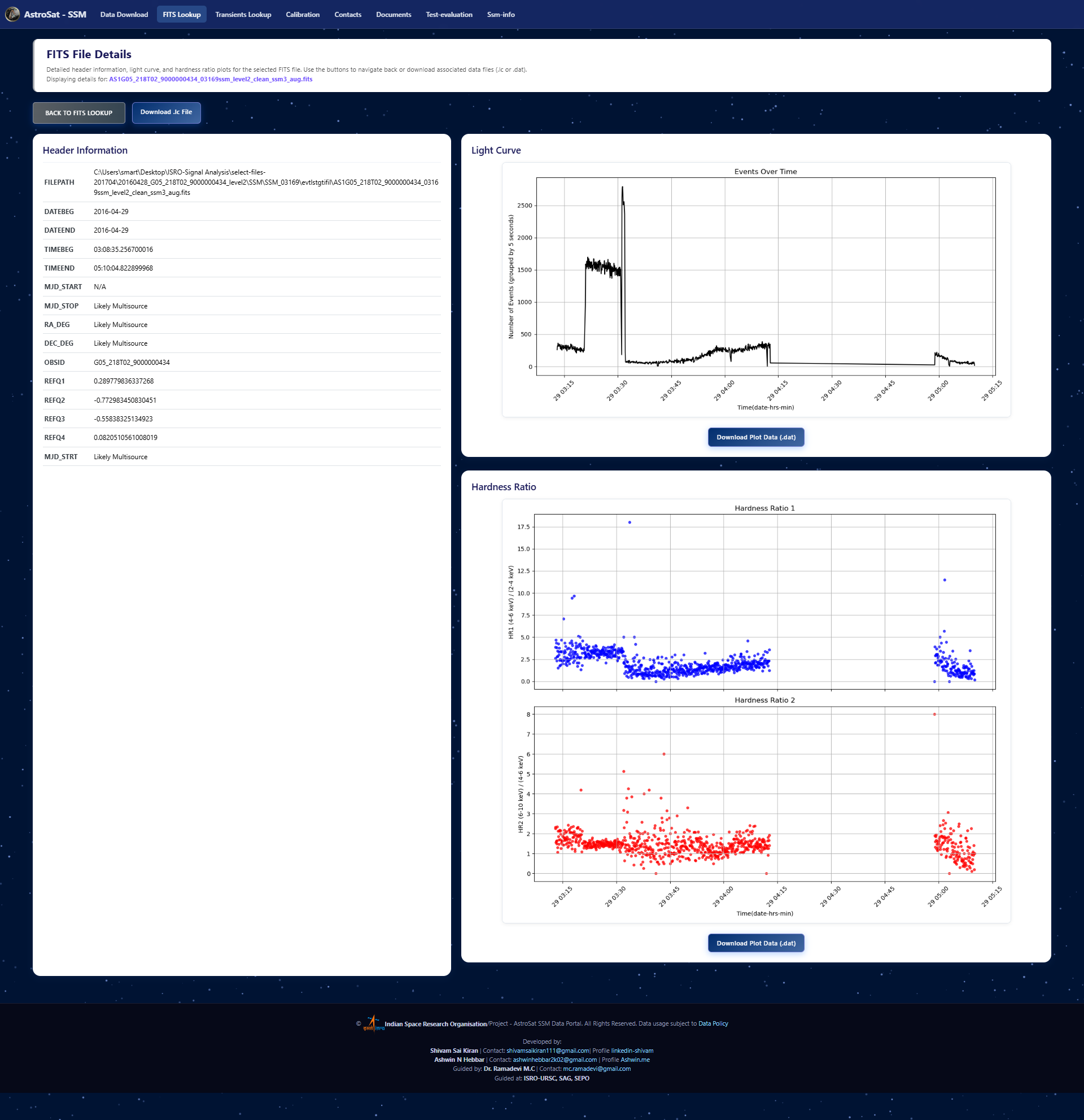
FITS File Table Inspector
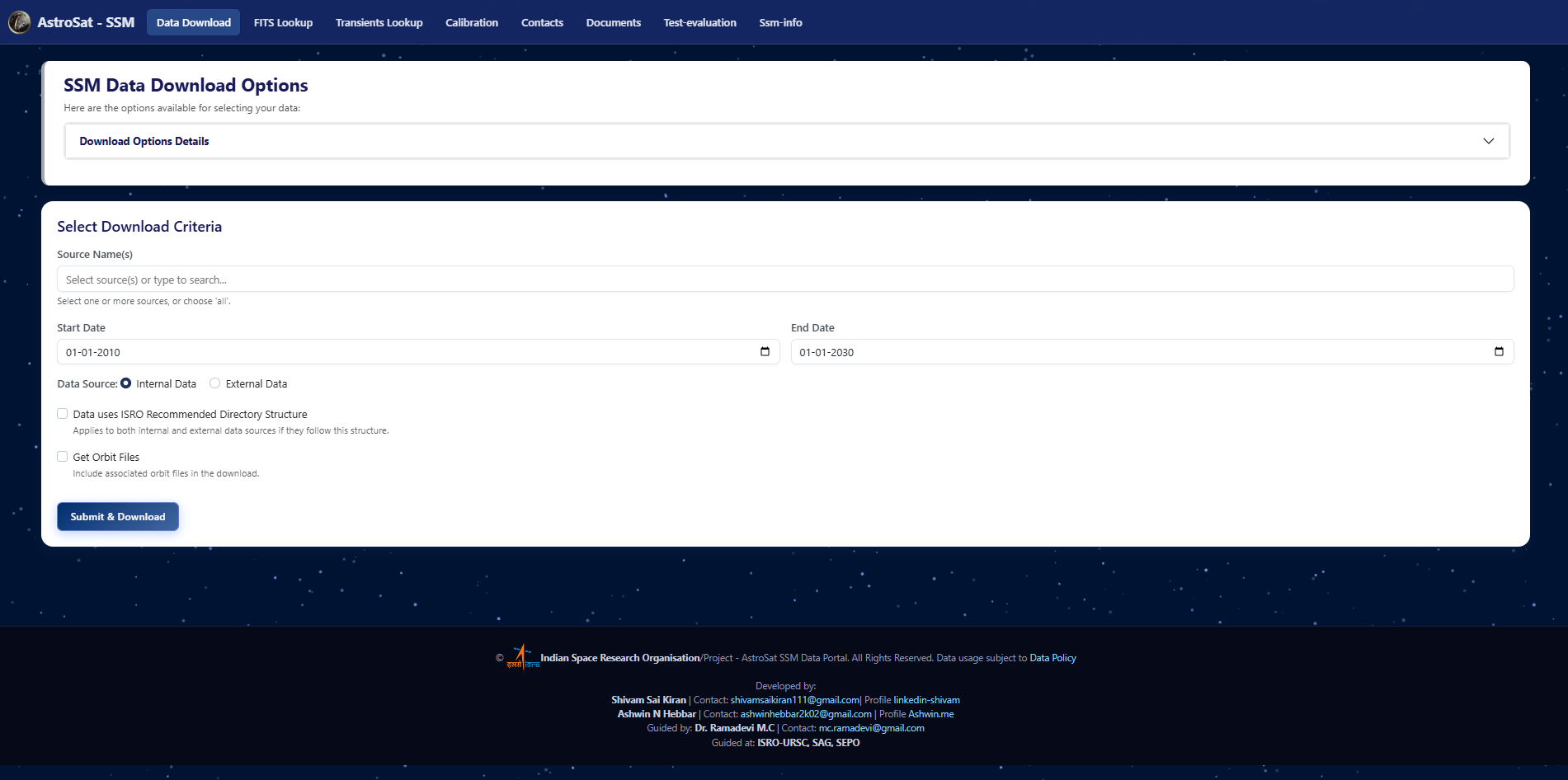
SSM Data Extract Portal
Markdown CMS for SSM Information
Impact Points
- Engineered a scientific data platform to process and distribute a 14 TB astrophysical data archive from the AstroSat satellite, serving a global community of researchers.
- Architected the core data extraction pipeline in Python and Pandas, reducing complex query times from hours to minutes (>95% improvement) and handling massive 100 GB+ aggregated datasets through intelligent file splitting.
- Implemented a high-performance caching layer using MD5 hashing, slashing processing time for repeat queries by over 99% (from 15+ minutes to ~3 seconds) and significantly reducing server load.
- Solely developed a dynamic Markdown-to-HTML CMS using Flask, empowering ISRO scientists to manage web content directly, which was lauded as an ‘outstanding’ feature by the project lead.