Building a Gen-AI Pipeline to Localize and Reformat Educational Content
As an Agentic AI Intern at USDC Global, there existed a long term challenge: how can we take dense, monolithic academic materials and transform them into something more engaging, accessible, and inclusive for a diverse student body? A simple script wouldn’t suffice; this required a scalable, maintainable, and extensible system.
In this post, I’ll walk you through how I architected and developed a sophisticated pipeline that ingests raw PDFs, intelligently deconstructs them into “Byte-Sized Learning Modules,” and translates them into multiple languages, complete with rigorous quality checks. The initial vision for this project was conceived by my mentor and guide, Dr. Raja Subramanian (Head, Learning & Innovations Team), who empowered me to architect the solution.
The Challenge: Beyond a Simple Script
The business problem was clear:
- English-only PDFs were creating a barrier to learning.
- These English-only PDFs were dense, presenting a challenge for students to engage with the material.
The technical challenge was more nuanced. We needed a system that could not only solve the immediate problem but also adapt to future needs. How could we design a framework that could:
- Easily incorporate new AI models from different providers (like OpenAI or Cohere) without rewriting the core logic?
- Allow for new processing capabilities (e.g., summarization, question-generation) to be added as simple plug-ins?
- Be robust, testable, and maintainable in the long run?
The answer lay in a deliberate, object-oriented design centered on abstraction and polymorphism.
My Solution: An Architecture for Scale and Extensibility
I designed and built an extensible framework built upon two core architectural pillars:
- A Standardized
ProcessingStepHierarchy: Every action in the workflow—from initial PDF parsing to translation—is treated as a “Step.” Each step inherits from a commonProcessingStepAbstract Base Class (ABC), forcing it to have a standard interface (.execute()). This makes the pipeline itself incredibly simple: it’s just a sequence of these interchangeable steps. - A Pluggable
ModelProviderLayer (Strategy Pattern): All interactions with external LLMs are handled through aModelProviderABC. Concrete implementations (we currently haveGeminiProvider,BedrockNovaProvider) encapsulate the provider-specific API calls. This decouples the pipeline’s logic from the specific AI model being used, allowing us to switch between them with a single configuration change.
This design transforms the system from a rigid script into a flexible, powerful framework.
Architecture Deep Dive: A Walkthrough of the Pipeline
The following diagram illustrates the flow of data and control through the system I designed.
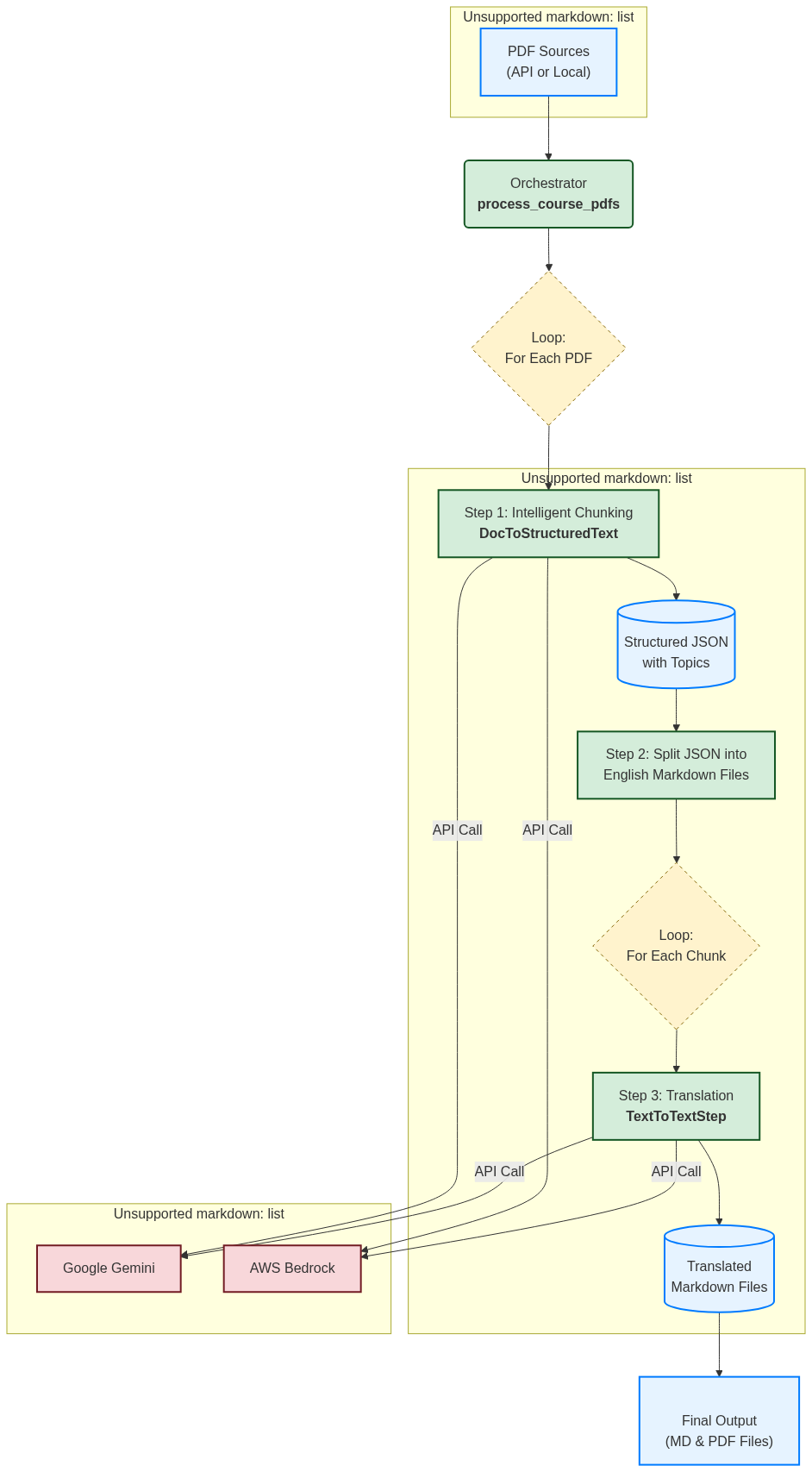
Deconstructing the Workflow:
- Ingestion: A dedicated module fetches a list of PDFs from an API or local directory.
- Orchestration: The main orchestrator iterates through the list. For each document, it initiates a
TranslationPipelineinstance. - Structured Extraction: The pipeline’s first action is executing a step that converts these pdfs into semantically chunked, english files. This custom
ProcessingStepsubclass sends the PDF to the configuredModelProviderand parses the response into simple chunks. - Translation & Formatting: The orchestrator then iterates through these chunks. For each chunk, the
TranslationManagergenerates a sequence of tranlslation objects (e.g., for English-to-Hindi, English-to-Kannada). The pipeline executes these steps, again using theModelProviderto perform the translation. - Publishing: Finally, the system saves the translated content to markdown files. A final, optional step converts these into polished PDFs using Typst.
The elegance of this design is that the main TranslationPipeline loop is incredibly simple and agnostic. It just runs the .execute() method on whatever ProcessingStep objects it is given, without needing to know the specifics of their implementation.
Technology Stack
- Language: Python 3.10
- AI & LLMs: Google Gemini, AWS Bedrock (Amazon Nova, Anthropic Claude)
- Data Handling: Pandas
- Cloud & API:
boto3,google-genai,requests - Document Processing: Typst (for Markdown-to-PDF generation)
- Architecture: Object-Oriented Design, Strategy Pattern, Factory Pattern, Abstract Base Classes
Key Technical Challenges & My Solutions
1. Ensuring Reliable Structured Output from LLMs While Gemini offers a native JSON mode, some models on AWS Bedrock do not. These models would occasionally return malformed JSON or add conversational text, breaking the pipeline.
- Solution: I developed a robust prompt engineering strategy that included providing the exact JSON schema, few-shot examples, and explicit negative constraints (e.g., “Do not include any text before or after the JSON object.”). This disciplined prompting increased the reliability of valid JSON responses from non-native models to near 100%. Use of stop sequences further ensured that the model output was clean and parsable.
2. Rigorous Quality Assurance for Translations “How good is the translation?” is a critical question. A simple back-translation might be misleading if the model hallucinates in both directions.
- Solution: I implemented a highly rigorous validation step. After a translation, a
BackTranslationstep (another subclass ofTranslationStep) would reverse the process. This back-translated text was then compared to the original English source using A provider of choice. Setting the temperature to zero makes the model’s output deterministic and analytical, allowing it to act as an objective semantic judge. This approach yielded a quantifiable similarity score, consistently proving to be over 97% accurate semantically.
Impact and Results
This project successfully transitioned from a conceptual idea to a production-ready pipeline, delivering significant and measurable value:
- Complete Automation & Unprecedented Speed: I automated a brand-new content workflow. The pipeline can process an entire course of 15 large PDFs—including chunking and translation into 3 languages—in under 30 minutes.
- Proven Scalability: The system has been tested on a corpus of over 300 source PDFs (~1 GB in total), demonstrating its stability and readiness for large-scale deployment.
- High-Fidelity Content Preservation: The intelligent chunking process successfully preserved complex academic content, including LaTeX mathematical formulas, data tables, and nested lists, during the PDF-to-Markdown conversion.
- Quantifiable & Verified Quality: Translation quality was validated at scale, achieving >97% semantic similarity in automated tests and receiving positive confirmation from manual reviews by native speakers.
- Demonstrated Framework Versatility: To test its limits, the framework was applied to a completely different domain: translating Hindi Jain religious texts into English for a new company initiative. Its success in this unrelated task highlighted the true language- and domain-agnostic nature of the architecture I designed.