Project Overview
I developed a comprehensive, multi-stage AI pipeline to automate the verification of Andhra Pradesh Class X academic certificates. This system addresses the costly and error-prone nature of manual verification, a process that can take 5-15 minutes per document. The solution I built identifies the correct documents with 95% accuracy, extracts key academic data with over 90% field-level accuracy, and presents the results in an interactive web application, as shown above. The entire automated pipeline completes a full verification in under 25 seconds, demonstrating a dramatic efficiency gain of over 90% and showcasing a practical application of modern AI.
The Problem: The Manual Verification Bottleneck
Universities, background verification agencies, and employers process thousands of academic certificates annually. This traditional manual verification is a significant operational bottleneck, characterized by:
- High Turn-Around Time (TAT): Each certificate can take 5 to 15 minutes for a human to locate, validate, and transcribe, creating significant backlogs.
- Error-Prone: Manual data entry is inherently susceptible to human error, leading to data integrity issues.
- High Operational Cost: The process requires dedicated staff and a significant investment in man-hours, making it expensive to scale.
My goal was to design an intelligent, end-to-end system to automate this entire workflow, delivering a solution that is fast, accurate, and scalable.
My Solution: A Three-Stage AI Pipeline
I engineered a sequential pipeline where each stage intelligently filters and processes the data for the next. This architecture ensures that each step is focused on a specific task, maximizing accuracy and efficiency throughout the workflow.
Tech Stack
- Backend & ML: Python, PyTorch, Ultralytics (YOLOv11), PaddleOCR, Ollama
- Models:
YOLOv11m-cls,Qwen-Coder-7.6B(4-bit quantized) - Frontend & Deployment: Streamlit
- Tools: AWS S3, Git, Albumentations
Stage 1: Document Classification with YOLOv11
The first challenge was to ensure the system only processes valid AP Class X certificates. My initial approaches proved that a naive dataset could lead to biased models. The successful approach required a complete overhaul of the data strategy.
- The Data Challenge & Curation: A robust model requires high-quality data. The foundation of this project was two weeks of dedicated effort to manually review, sort, and label a raw dataset of over 9,500 unsorted student documents. This meticulous process of creating clean, representative, and properly split training, validation, and test sets was the single most important factor in the project’s success.
- Model Selection & Training: I fine-tuned a
YOLOv11m-clsmodel, chosen for its excellent balance of high accuracy and efficient inference speed. - Result: The final model’s performance on the unseen test set was excellent. It achieved a 95% validation accuracy with healthy, converging loss curves. The detailed classification report below confirms its ability to correctly identify both positive (AP Cert) and negative (Not AP Cert) cases with high precision and recall.
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| AP Cert | 0.90 | 0.96 | 0.93 | 67 |
| Not AP Cert | 0.95 | 0.90 | 0.93 | 69 |
| --- | ||||
| Accuracy | 0.93 | 136 | ||
| Macro Avg | 0.93 | 0.93 | 0.93 | 136 |
| Weighted Avg | 0.93 | 0.93 | 0.93 | 136 |
Stage 2: Information Extraction with a Local LLM
Once a document is classified as authentic, the next step is to extract key information.
-
Tech Stack: I selected
PaddleOCRfor its superior text recognition and ran a quantized Qwen-Coder 7.6B model locally using Ollama. This ensures 100% data privacy and eliminates API costs. -
Advanced Prompt Engineering: I employed a Few-Shot Learning strategy. The key insight was that a cleaner prompt yielded better results. By removing noisy data like OCR bounding box coordinates and providing clear instructions and examples, I guided the model to perform a complex structured extraction task without explicit fine-tuning
-
Result: This prompt engineering resulted in a highly reliable extraction pipeline. The LLM correctly identified and formatted the data into the desired JSON structure with over 90% field-level accuracy.
{
"candidate_name": "<Student Name?",
"school_name": "<School Name>",
"exam_month_year": "MARCH 2016",
"gpa": 7.3,
"exam_outcome": "passed",
"medium_of_instruction": "english",
"date_of_birth": "04/05/2001",
"subject_scores": {
"First Language (Telugu)": 8,
"Third Language (English)": 7,
"Mathematics": 8,
"General Science": 6,
"Social Studies": 8,
"Second Language (Hindi)": 7
}
}
Stage 3: Interactive Demo with Streamlit
As shown in the application screenshot at the top of this post, I built a fully functional user-friendly interface using Streamlit. It allows a user to upload a certificate and see the results of the classification and extraction stages in a clear, digestible format, completing the proof-of-concept.
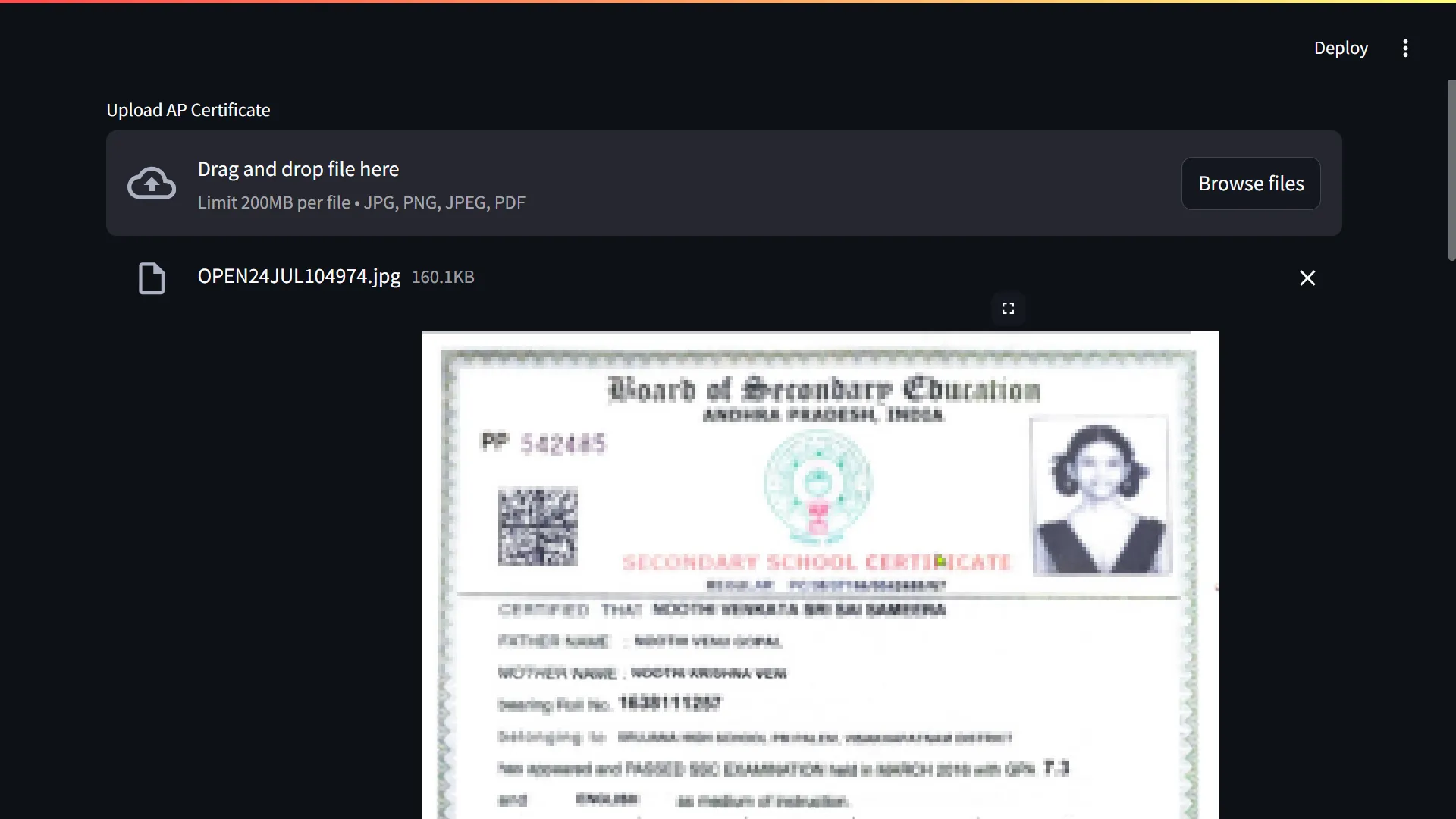
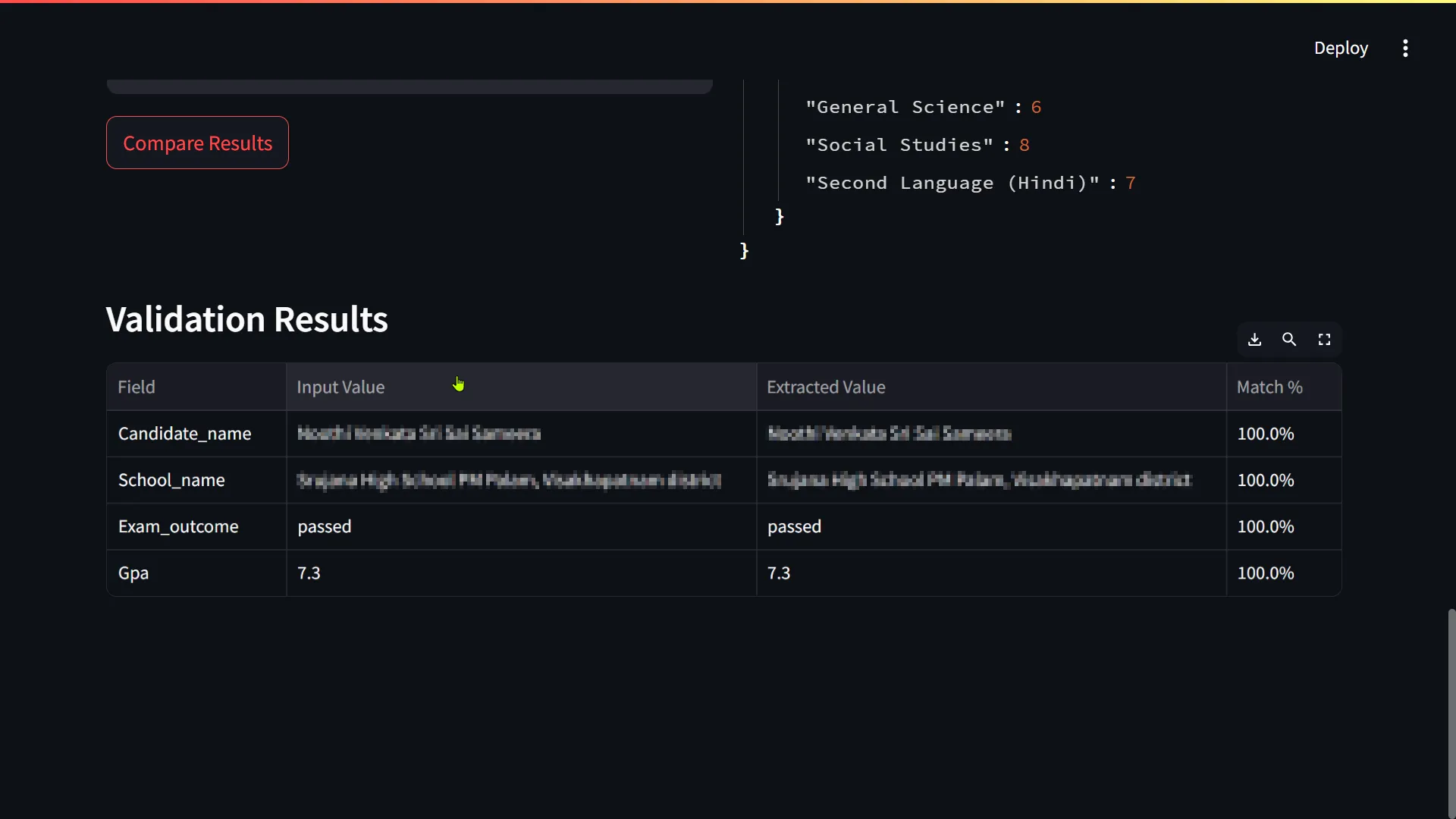
Key Achievements & Impact
- Efficiency: Reduced document processing time from 5+ minutes to under 25 seconds, an enormous efficiency improvement of over 90%.
- Accuracy: Delivered a highly reliable pipeline with 95% classification accuracy and >90% information extraction accuracy.
- Cost & Privacy: Designed a solution using open-source models hosted locally, ensuring zero API costs and guaranteeing that sensitive student data is never exposed to third-party services.
- Grit & Iteration: Successfully navigated multiple failed approaches, diagnosing and solving complex issues with data bias before arriving at a robust, well-architected final solution.